Transforming Data Landscapes: A Deep Dive into AWS Glue ETL

I am a DEVOPS ENGINEER from Pune, Maharashtra. Currently a working professional with 2 years of experience.
What is ETL?
ETL stands for Extract, Transform, Load, and it refers to a process in data integration where data is extracted from source systems, transformed into a desired format, and then loaded into a target system, typically a data warehouse or a data mart. The ETL process is a crucial component in the data pipeline, especially when dealing with large volumes of data and heterogeneous data sources.
Here's a breakdown of the three main phases in the ETL process:
Extract:
In the extraction phase, data is collected from various source systems. Source systems could include databases, applications, logs, flat files, APIs, and more.
The goal is to retrieve relevant data needed for analysis or reporting.
Transform:
Once the data is extracted, it undergoes transformation to meet the requirements of the target system or application. Transformations may include cleaning and validating data, aggregating values, filtering records, and converting data types.
The transformation phase ensures that the data is consistent, accurate, and in a format suitable for analysis.
Load:
After the data has been transformed, it is loaded into the target system, which is often a data warehouse or a database optimized for reporting and analytics.
Loading involves writing the transformed data into the target database or data store, making it available for querying and reporting.
The ETL process is essential for maintaining data quality, consistency, and integrity across different systems. It helps organizations centralize and organize their data, making it easier to analyze and derive insights. ETL is commonly used in business intelligence, data warehousing, and data migration scenarios.
With the rise of cloud computing, there are now managed ETL services, such as AWS Glue, Azure Data Factory, and Google Cloud Dataflow, that automate and streamline the ETL process, providing scalability, flexibility, and serverless execution environments.
What is AWS Glue?
AWS Glue is a fully managed extract, transform, and load (ETL) service provided by Amazon Web Services (AWS). It is designed to help users prepare and load their data for analysis quickly and easily. AWS Glue simplifies the ETL process by automatically discovering, cataloging, and transforming data from various sources.
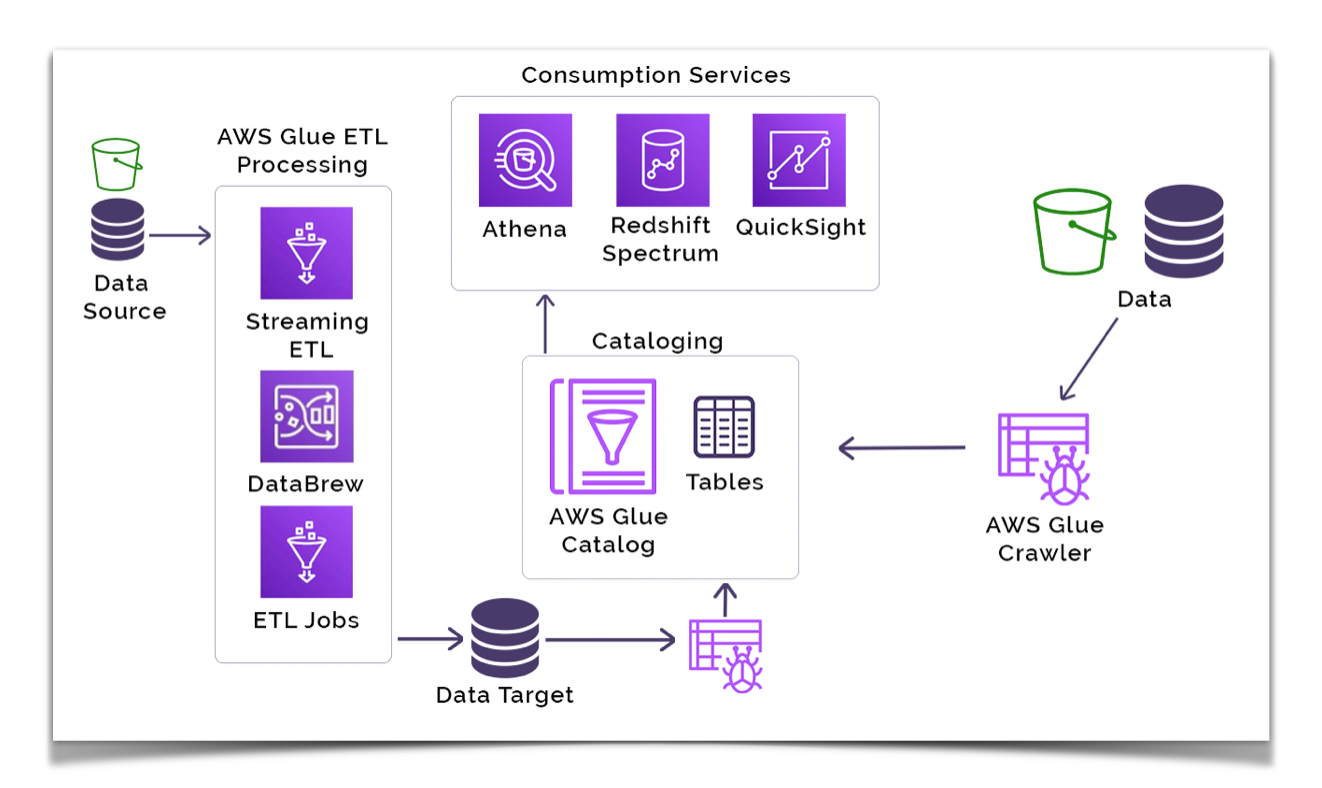
Components of AWS Glue
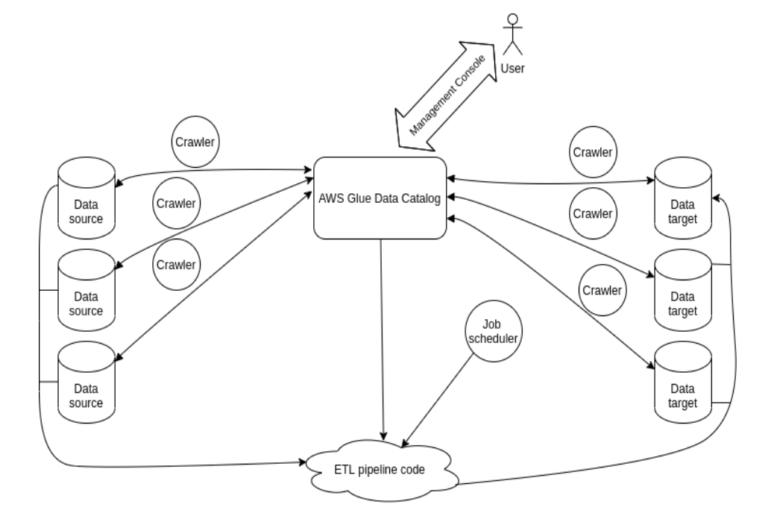
AWS Glue is comprised of several key components that work together to provide a fully managed ETL (Extract, Transform, Load) service. Here are the main components of AWS Glue:
Data Catalog:
The AWS Glue Data Catalog is a centralized metadata repository that stores metadata about data sources, transformations, and targets.
It provides a unified view of your data assets across different AWS services and on-premises databases.
The Data Catalog is shared across AWS services, enabling seamless integration with services like Amazon Athena, Amazon Redshift, and Amazon EMR.
Crawlers:
Crawlers are automated processes in AWS Glue that connect to your source or target data store and infer the schema and statistics of your data.
Crawlers discover tables, partitions, and the underlying schema, updating the Data Catalog with metadata.
They play a crucial role in automatically cataloging and organizing data from various sources.
ETL Jobs:
AWS Glue ETL jobs are the core processing units that perform the data transformations.
ETL jobs can be created using the AWS Glue Console or scripted using Python or Scala.
The underlying ETL engine is based on Apache Spark, and AWS Glue manages the Spark infrastructure for you.
Development Endpoints:
Development endpoints provide an environment for developing, testing, and debugging your ETL scripts before deploying them to production.
They allow you to interactively develop and run Spark scripts on a provisioned environment.
Triggers:
Triggers in AWS Glue allow you to automate the execution of your ETL jobs based on events or schedules.
You can set up triggers to run jobs when new data is available or on a regular schedule.
DynamicFrames:
DynamicFrames are an abstraction on top of Apache Spark DataFrames, introduced by AWS Glue to handle semi-structured data.
They provide a flexible and efficient way to work with diverse data formats and structures.
Classifiers:
Classifiers in AWS Glue are used during the crawling process to classify the format and structure of the source data.
AWS Glue includes built-in classifiers for common data formats like JSON, CSV, Parquet, and others.
Connections:
Connections in AWS Glue store connection information for data stores, allowing you to securely connect to databases, cloud storage, or other data sources.
They include connection details such as endpoint, port, username, and password.
Security Configurations:
Security configurations in AWS Glue enable you to specify encryption settings for your ETL jobs.
They help ensure that data is encrypted in transit and at rest, providing a secure environment for data processing.
These components work together to provide a fully managed, scalable, and serverless ETL solution in AWS Glue, allowing organizations to prepare and transform their data for analytics and reporting without the need for infrastructure management.
ETL process using AWS Glue
The following process is used to create an ETL job using AWS Glue.
Creating an IAM role for AWS Glue
To create an IAM (Identity and Access Management) role for AWS Glue, you'll need to follow these general steps. IAM roles define a set of permissions for AWS services, and they allow AWS resources to securely interact with each other.
Here's a step-by-step guide to creating an IAM role for AWS Glue:
Sign in to the AWS Management Console:
- Go to the AWS Management Console at https://console.aws.amazon.com/.
Navigate to IAM:
- In the AWS Management Console, find the "Services" dropdown, and under the "Security, Identity, & Compliance" category, click on "IAM" (Identity and Access Management).
Select "Roles" in the left navigation pane:
- In the IAM dashboard, click on "Roles" in the left navigation pane.
Click "Create role":
- Click the "Create role" button to start the process of creating a new IAM role.
Choose the service that will use this role:
- In the "Select type of trusted entity" section, choose the service that will assume the role. For AWS Glue, you might select "AWS Glue."
Attach permissions policies:
In the "Permissions" section, attach policies that grant the necessary permissions to the role. You can use existing policies or create custom policies based on your specific requirements.
AWS provides managed policies for AWS Glue, such as
AWSGlueServiceRolethat you can attach for common Glue-related permissions.
Add tags (optional):
- Optionally, you can add tags to your role to help organize and identify it.
Review and name the role:
- Give your role a meaningful name and description so you can easily identify its purpose.
Review your choices:
- Review the role's configuration to ensure it meets your requirements.
Create the role:
- Click the "Create role" button to create the IAM role.
Once the role is created, you'll see a summary page for the role. Take note of the role's ARN (Amazon Resource Name), as you'll need it when configuring AWS Glue jobs.
After creating the IAM role, you can associate it with your AWS Glue jobs or crawlers by specifying it during the job or crawler creation process. This role determines the permissions that the Glue service has to access other AWS resources on your behalf.

Uploading your raw data to S3 bucket
Adding raw data to an Amazon S3 (Simple Storage Service) bucket involves a few steps.
Navigate to Amazon S3:
- Find the "Services" dropdown and under the "Storage" category, click on "S3" to navigate to the S3 console.
Create a new S3 bucket :
If you don't have an S3 bucket yet, create one by clicking the "Create bucket" button.
Follow the instructions to choose a bucket name, region, and configure any additional settings.
Access the S3 bucket:
- Click on the name of the S3 bucket you want to upload data to.
Upload data:
Inside the bucket, click on the "Upload" button to upload your raw data files.
Use the file upload wizard to select and upload one or more files. You can also drag and drop files directly.
Set permissions (optional):
- Depending on your requirements, you might want to set appropriate permissions for the uploaded files or the entire bucket. You can configure permissions on the "Permissions" tab of your bucket.

Creating Glue Jobs
Creating Glue jobs is a process which involves many steps.
1. Create a Database:
Create a Database:
Click on "Databases" in the left navigation pane.
Click on "Add database" and provide a name for your database.
2. Define a Data Catalog:
Add Tables to Data Catalog:
Navigate to the database you created.
Click on "Tables" and then "Add tables."
You can manually add tables or use crawlers to automatically discover and catalog your data.
3. Using Crawlers for creating tables:
Crawlers can be used to create tables for databases. Navigate to thye cralwers section and then click on create a new crawler

Choose data sources in Is your data already mapped to Glue tables? as not yet.

Now add data source as S3 and upload the path of your S3 bucket which has your raw data.

Now use the IAM role which we had created

Now finally select the database for storing the output and finally create the crawler.


You can also see that the table is created now

Creating Jobs using AWS Glue
Navigate to ETL jobs in AWS Glue and click on Visual ETL.

You can add source as AWS Glue catalog
Click on it after creating and you can see the properties of it and then select the database which we had created earlier.

Now we have to add node for
transformsand we can selectchange schemas
Inside change schemas we can select the appropriate transformations by selecting on it which is the main step here for transforming data.
And in
targetswe can select asS3
Finally we can save the job and run the job.

After running the job you can see the transformed data been created and stored into S3 bucket.

Conclusion
In conclusion, storing data from AWS Glue to Amazon S3 buckets is a fundamental step in building scalable and efficient data pipelines. This article has explored the seamless integration between AWS Glue and S3, providing a robust solution for Extract, Transform, Load (ETL) processes. By leveraging Glue's ETL capabilities and S3's scalable object storage, organizations can achieve high-performance data processing and storage with ease.
Key Takeaways:
AWS Glue Simplifies ETL: AWS Glue offers a serverless and fully managed environment for ETL jobs, eliminating the need for infrastructure management. The visual tools and scripting options make it user-friendly for data engineers and analysts.
Data Catalog with Glue: The AWS Glue Data Catalog plays a pivotal role in managing metadata and schema information. Crawlers automate the discovery and cataloging of data, creating tables that can be utilized in ETL jobs seamlessly.
Integration with S3: Amazon S3 serves as a highly scalable and durable storage solution for the data processed by Glue. The integration ensures that data can be efficiently stored, retrieved, and analyzed, making it a preferred choice for diverse data storage needs.
Cost-Efficient Scalability: Both AWS Glue and S3 offer a pay-as-you-go model, allowing organizations to scale their resources based on demand. This cost-efficiency is crucial for managing data-intensive workloads without incurring unnecessary expenses.
Security and Compliance: AWS Glue and S3 prioritize security, providing features such as encryption, access controls, and audit trails. This ensures that sensitive data is protected and organizations can meet compliance requirements.
Automated Workflows: By leveraging AWS Glue jobs and S3, organizations can automate their data workflows, reducing manual intervention and improving overall efficiency. Scheduling options enable regular updates, keeping data pipelines up-to-date.
In conclusion, the combination of AWS Glue and Amazon S3 empowers organizations to build robust and scalable data architectures. Whether dealing with large datasets, streaming data, or diverse sources, this integration provides the flexibility and tools needed to architect modern data solutions on the AWS cloud. As technology evolves, staying informed about best practices and updates from AWS will be key to optimizing data storage and processing workflows.


